
소연이의 메모장
유전 알고리즘을 활용한 음식 배달 최적화 기법 본문
자, 나의 첫 논문이다.
어디 내놓기 부끄럽지만 혹시 나와 같은 어려움을 겪는 사람들이 있을까 봐 코드까지 공개한다.
궁금하면 클릭🖱
혹시 틀린게 발견되면.. 혼자만 알고 계셔 주세요 ㅎㅎ
농담이고 댓글주세요 ~ 이렇게 발전하는 거죠!
- 연구문제 : 배달 업무의 고른 분배를 통해 배달원들의 경쟁을 완화하고 전체 배달 시스템의 처리량과 신뢰도 향상
- 문제 정의 : 처리량은 배달 건 수의 표준편차, 신뢰도는 시간 내에 배달을 완료하는 것
- 사용한 데이터 : 미국의 배달 업체 Grubhub 데이터 사용 [궁금하면 오백원]
- 유전 알고리즘 사용 이유 : 목적함수의 최적화와 무작위성이라는 특징을 가지고 있기 때문
1. 데이터 살펴보기
데이터는 총 다섯 세트로 구성되어 있으며
사용할 데이터는 음식점 위치, 배달원 위치, 수령인 위치 데이터다.
각 위치의 분포를 살펴보면 아래와 같다.

음식점은 빨강, 배달원은 청록, 수령인은 노랑처럼 분포되어 있다.
배달원은 대체적으로 퍼져있고 음식점은 몰려 있으며 수령 위치 또한 상대적으로 오밀조밀하다.
아마도 10000,8000 좌표쯤이 도심지인 것 같다.
아래는 시간대 별 배달원 근무시각과 음식 주문 및 준비 시각이다.
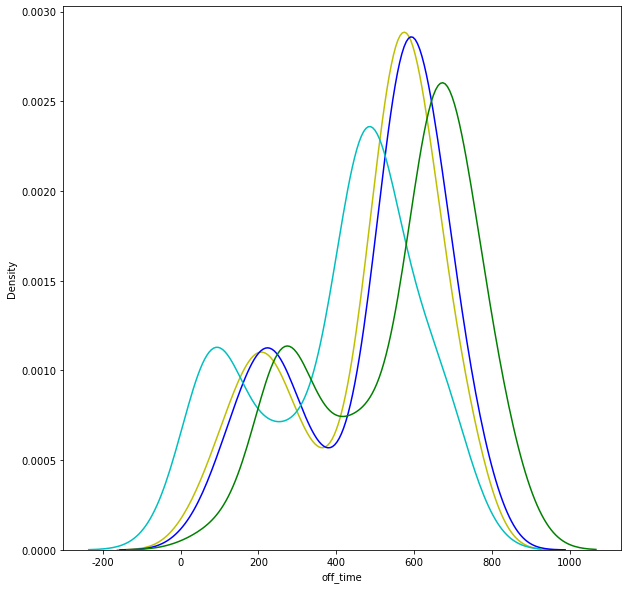
시간대를 살펴보면 음식 주문이 600 근처에 몰리기 때문에
배달원들은 그 시간대 전후로 근무하는 것을 볼 수 있다.
2. 소스코드
일부만 공개하는 것이기 때문에 복붙 하면 오류 납니다. 참고용이에요.
# 데이터 불러오기
import numpy
import pandas as pd
import pygad
restaurant = pd.read_csv("./음식점데이터.csv")
rider = pd.read_csv("./배달원데이터.csv")
data_len = len(rider)
print("오더 수", len(restaurant))
print("라이더 수", data_len)
>> 오더 수 209
>> 라이더 수 61
## 209건의 주문을 수행할 수 있는 배달원은 현재 61명이다.
# 배달원 정보 불러오기
delivered_num = numpy.random.uniform(low=3, high=25, size=data_len).astype(int) ## 배달 건 수
dist_x = numpy.array(rider['x']) ## 배달원 X좌표
dist_y = numpy.array(rider['y']) ## 배달원 y좌표
on_time = numpy.array(rider['on_time']) ## 배달원 출근시간
off_time = numpy.array(rider['off_time']) ## 배달원 퇴근시간
speed = numpy.random.uniform(low=30, high=60, size=data_len).astype(int) ## 배달원 속도
trustiness = numpy.full(data_len, 0.9) ## 시간 내 배달 완료한 경우
## 배달원 정보에 따른 초기값 설정
new_population = numpy.stack((delivered_num, dist_x, dist_y, on_time, off_time, speed, trustiness), axis=0)
# Function inputs.
function_inputs = new_population
# desired_output : 배달 건 수, x좌표, y좌표, 출근시간, 퇴근시간, 속도, 신뢰도 순
desired_output = numpy.array([[0],[2875],[3459],[400],[700],[1],[1]])
# 목적함수 설정
def fitness_func(solution, solution_idx):
solution = solution.reshape(7,61)
## 배달 건 수의 표준편차 고려
std = numpy.std(solution[0])
log_std = numpy.log1p(std)
## 최대한 안전하게 달리는 속도
speed = solution[5]
sc_speed = ((speed - min(speed)) / (max(speed) - min(speed)))
## 시간 내 배달이 도착한다는 믿음
trust = solution[0] / (solution[4]- solution[3])
sc_trust = ((trust - min(trust)) / (max(trust) - min(trust)))
## 표준편차는 낮게, 속도와 신뢰도는 높을수록 적합도 함수가 증가
fitness = (1/log_std) + (sc_speed + sc_trust)
return fitness[0]연구 목적에 따라 위와 같이 초기값을 설정해 주고
유전 알고리즘을 실행한다.
fitness_function = fitness_func
def on_start(ga_instance):
print("on_start()")
def on_fitness(ga_instance, population_fitness):
print("on_fitness()")
def on_parents(ga_instance, selected_parents):
print("on_parents()")
def on_crossover(ga_instance, offspring_crossover):
print("on_crossover()")
def on_mutation(ga_instance, offspring_mutation):
print("on_mutation()")
def on_generation(ga_instance):
print("on_generation()")
def on_stop(ga_instance, last_population_fitness):
print("on_stop()")
########### pop 100
ga_instance = pygad.GA(num_generations=1000,
num_parents_mating=4,
fitness_func=fitness_function,
sol_per_pop=500,
num_genes=len(function_inputs)*len(function_inputs[0]),
save_best_solutions=True,
on_start=on_start,
on_fitness=on_fitness,
on_parents=on_parents,
on_crossover=on_crossover,
on_mutation=on_mutation,
on_generation=on_generation,
on_stop=on_stop)
ga_instance.run()
# 결과에 따른 그래프
ga_instance.plot_fitness()
그럼 표준편차는 0.2에 가까워지고 절반 가까이 시간 내 배달을 완료하였다는 것을 확인할 수 있다.
Fitness value of the best solution = 2.53388275048413
Index of the best solution : 1
Predicted 표준편차 based on the best solution : 0.2606841548696163
Predicted 신뢰도 based on the best solution : 0.5340214330193552
Best fitness value reached after 20 generations.논문을 작성할 땐 여기서 좀 더 보완을 했지만 기본 틀은 비슷하다.
사실 이런 pdptw 문제를 풀 땐
유전 알고리즘 같은 클래식한 기법보다는 강화학습이 더 적절할 것이라고 생각한다.
그건 내 미래 과제로 남겨두었다.
이제 진짜 유전알고리즘 끝!
조만간 LSTM 시계열 알고리즘으로 돌아오겠다.
'ML\DL > 알고리즘의 이해' 카테고리의 다른 글
| PyGAD를 활용한 유전 알고리즘의 구현 (1) | 2023.10.02 |
|---|---|
| Genetic Algorithm(GA) 유전 알고리즘의 이해 (0) | 2022.08.24 |

